../
Learning the basics of the Datasette ecosystem with crates.io data
Published: , updated:
Background
I’ve been enjoying exploring the data from the Bevy game jam, and wondered what other ways one could come up with an idea of the popular/active Bevy ecosystem using data. One speculative investigation involves understanding the time taken from a new Bevy minor version (since Bevy is still pre-1.0, this means a breaking change) and when various Bevy dependents (libraries and games/apps) are updated.
The simplest option here is to look at crates.io, which helpfully provides a few different means of data access. One of these is a database dump, which gave me an excuse to finally use the Datasette ecosystem on a small project. Datasette’s tagline is “Find stories in data”, which is very much what I’m trying to do.
Getting the dump
The database dump has a fixed URL which uses a redirect to a fixed per-object URL. The archive stores the data in a folder named with the time of the database dump.
$ curl -OL https://static.crates.io/db-dump.tar.gz
$ tar xzf db-dump.tar.gz
$ cd 2023-07-.../data
Data import and transformation using sqlite-utils
Datasette is built around SQLite for various reasons. sqlite-utils is the part of the Datasette ecosystem for getting that SQLite database created - getting the data out of various other formats and into the “common language” of SQLite and from there whatever transformations you want to make. The crates.io database dumps are in the PostgreSQL language for the schema, but the data itself is stored in simple CSVs, which is something sqlite-utils is set up to handle well.
This could be as simple as:
$ sqlite-utils insert dump.db crates crates.csv --csv --detect-types
This would work, and with other steps, we could fix a few issues (for example, removing the “row id” primary key). But we also have full control if we want it, so instead we can do:
$ sqlite-utils create-table dump.db crates \
id integer \
name text \
homepage text \
repository text \
description text \
documentation text \
downloads integer \
created_at text \
updated_at text \
--not-null name \
--not-null homepage \
--not-null repository \
--not-null description \
--not-null documentation \
--not-null downloads \
--not-null created_at \
--not-null updated_at \
--pk=id
There were two columns I was fairly sure I didn’t care about, so I could remove them during the import:
$ sqlite-utils insert dump.db crates crates.csv --csv \
--convert 'del row["max_upload_size"], row["readme"]'
That --convert argument takes Python code that allows for essentially arbitrary modification of the CSV data during import - here it’s just deleting some data, but it could easy transform between types (say, string enumerations to integers), split data in one column to multiple, or join data from multiple columns to one.
For the second table, we can start with a naive import, and iterate from there:
$ sqlite-utils insert dump.db versions versions.csv --csv --detect-types
Datasette (as simple as running datasette dump.db and following the link) can then be used to look at the schema and data:

Naive import with arbitrary column ordering
The columns are in what seems to be arbitrary column ordering. There’s a generated row identifier that is the primary key, rather than using the id column. Going down to the schema itself shows the columns are all nullable. So, to fix that all up, we can do that iin a single command on the command line:
$ sqlite-utils transform dump.db versions \
-o id -o crate_id -o num -o rust_version -o created_at \
-o updated_at -o yanked -o downloads -o published_by -o features \
-o links -o license -o checksum \
--not-null checksum --not-null crate_id --not-null num \
--not-null created_at --not-null updated_at --not-null downloads \
--not-null yanked \
--pk=id
Once reloaded in Datasette, not only are the columns in a nice order (something I’m sure you could fix without updating the table itself), but the schema is closer to accurate.

Updated schema, with column ordering and primary key
If you want to test something out, easy enough to create a backup and do so:
$ sqlite-utils duplicate dump.db versions versions-backup
$ sqlite-utils convert dump.db versions \
yanked --output-type integer 'value == "t"'
This converts the yanked column from a boolean which is exported as t or f as text in the CSV into a SQLite integer.
Finally, we can recreate the foreign key between crates and versions:
$ sqlite-utils add-foreign-key dump.db versions crate_id crates id
In Datasette, now instead of showing the id of the crate, the crate’s name will be displayed by default (Datasette has a number of ergonomic defaults - in this case for foreign keys to tables with a column called name):
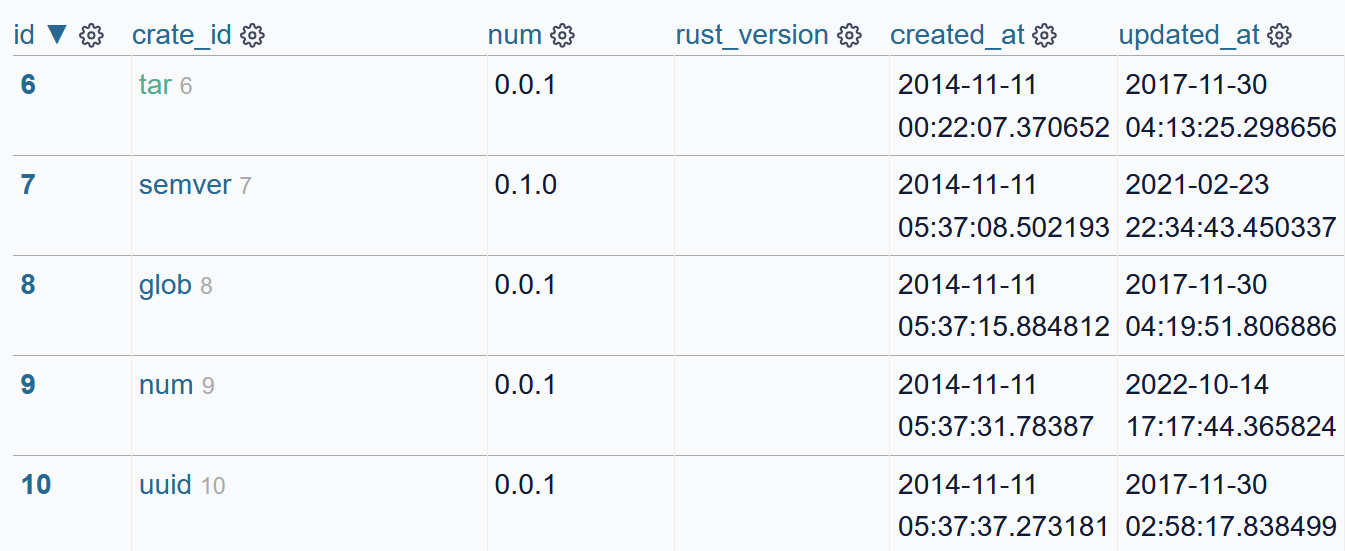
Foreign key to crates showing the crate name
In addition, when looking at a single row of crates, it’ll provide a link to see all the versions associated with it.
We could also bypass the crate-table “DSL” and create the tables by hand by essentially just using the PostgreSQL schema plus adding the foreign keys:
$ sqlite-utils query dump.db 'CREATE TABLE dependencies (
id integer NOT NULL PRIMARY KEY,
version_id integer NOT NULL,
crate_id integer NOT NULL,
req text NOT NULL,
optional boolean NOT NULL,
default_features boolean NOT NULL,
features text NOT NULL,
target text,
kind integer DEFAULT 0 NOT NULL,
explicit_name text,
FOREIGN KEY ([version_id]) REFERENCES [versions]([id]),
FOREIGN KEY ([crate_id]) REFERENCES [crates]([id])
);'
$ sqlite-utils insert dump.db dependencies dependencies.csv --csv
Data import using Datasette
So far, we haven’t really been using Datasette as anything beyond just a basic SQL table viewer, but it’s a lot more capable than that. It is extensible with plugins written as Python packages - 115 listed on the official plugin list at time of writing - and we can use some of these to allow us to import and transform tables too.
$ datasette install datasette-upload-csvs datasette-edit-schema
Datasette has a full authorization system under the hood that, with plugins, allows anything from locally issued user/password pairs to API tokens to single sign-on, and has a simple authentication option built-in for the root user, just by starting with a --root option. When using this option, it will print a per-start-up unique token for logging in as root:
$ datasette --root dump.db
http://127.0.0.1:8001/-/auth-token?token=5ccd...
Now the upload CSV option is available at /-/upload-csvs, accessible from the menu system. Upload a file, and it’ll create the table for it.
From the table view, you can now edit the schema:
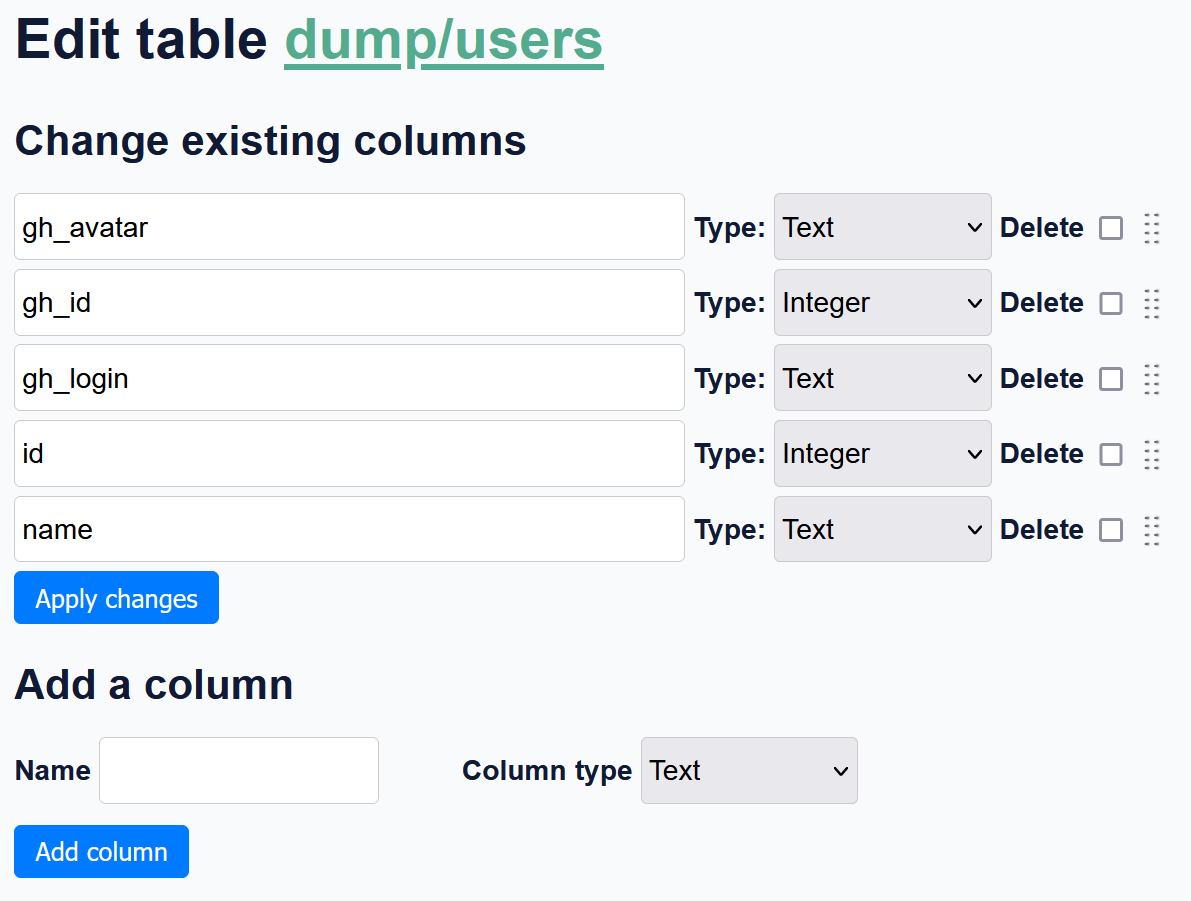
Editing the schema of a table in Datasette
This isn’t (yet) as powerful as the command-line sqlite-utils tools, but uses the same code, so could relatively easily be improved in the future to support more options - like adding foreign keys, setting primary keys, and so forth.
Creating views using sqlite-utils
$ sqlite-utils create-view dump.db dependencies_denormalized \
'select
versions.created_at,
crates_v.id AS dependent_crate_id,
crates_v.name AS dependent_crate_name,
versions.num AS dependent_crate_version,
dependencies.crate_id AS dependency_crate_id,
crates_d.name AS dependency_crate_name,
dependencies.req AS dependency_req,
kind
from dependencies
left join versions ON dependencies.version_id = versions.id
left join crates AS crates_v ON versions.crate_id = crates_v.id
left join crates AS crates_d ON dependencies.crate_id = crates_d.id'
This view will now show up in Datasette. SQLite itself is fast - querying this view for the first hundred entries is sub-1ms. However, Datasette does some operations in its default display for the view that make it take longer than expected, and may go past the default time limit.
One can turn up the time limit:
$ datasette dump.db --root --setting sql_time_limit_ms 5000
But we can also find out what Datasette is doing by logging in as root (ie, using the auth link that is printed when running with --root), whereupon it will show the specific query that was taking too long (in my case, SELECT COUNT(*) FROM ...).
We can also get the full list of queries executed when logged in by enabling query tracing:
$ datasette dump.db --root --setting sql_time_limit_ms 5000 \
--setting trace_debug 1
Then, adding a _trace query parameter set to 1 in your URL (appending ?_trace=1 to the URL in the simple case) will display a list of the queries and time taken to the page in JSON. Adding the datasette-pretty-traces plugin (installed with datasette install datasette-pretty-traces) will, unsurprisingly, make this prettier - with a timeline of queries:
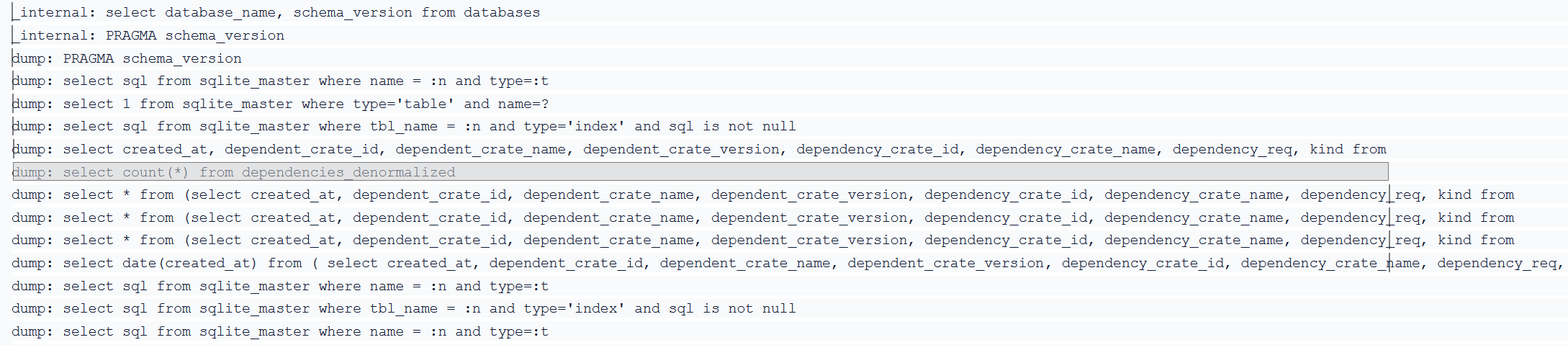
Trace of time taken for SQL queries for a Datasette page using datasette-pretty-traces
What’s next?
With the above, it’s trivial to get answers to questions like “When did each crate first get updated with a Bevy 0.11 requirement?”. Doing this for the previous two minor updates (0.9 and 0.10) might be enough to start seeing patterns - time taken from minor version to each crate being updated, lists of active crates from previous minor versions that aren’t yet updated for 0.11, and so forth. More on that, perhaps, later.